
Today's multimodal large language models can write code, interpret images, and hold long conversations. But ask one to generate a 3D model from text, and something strange happens: the language never reaches the geometry. Under the hood, most "text-to-3D" systems generate an image first, then feed that image into a reconstruction model that lifts pixels into mesh. The model doing the semantic reasoning never touches the 3D output. The model producing the geometry never reads the text.
This is a pipeline, not a model. And pipelines cannot edit.
EVA01 is our answer from first principles. It is a single Mixture-of-Transformers model that reads text, sees images, understands 3D meshes, generates new geometry, and edits across multiple turns — all within one sequence stream. No intermediate renderings. No external reconstruction. 3D mesh is a first-class modality alongside text and images.
In benchmarks, EVA01 achieves state-of-the-art text-to-3D fidelity with a Fréchet Distance of 122.48 (the next best text-to-3D model scores 238.45), 70.4% user preference in text-to-3D generation, and 93.75% user preference in multi-turn editing — where it operates without explicit edit masks. It is the only unified model ranked in the top two for both text-to-3D and image-to-3D.
Why One Tower Fails
Integrating 3D mesh generation into an MLLM seems straightforward: add a mesh tokenizer, expand the vocabulary, train end-to-end. But the optimization surfaces are mutually hostile.
Language understanding is trained with cross-entropy loss over discrete token predictions. 3D generation is trained with MSE loss over continuous geometric latents. CE updates that sharpen semantic prediction degrade the geometric manifold. MSE updates that improve surface quality erode the multimodal priors built through pretraining. Train both objectives under shared weights, and the model learns neither well.
The Mixture-of-Transformers architecture solves this by physically decoupling parameter spaces while keeping attention shared.
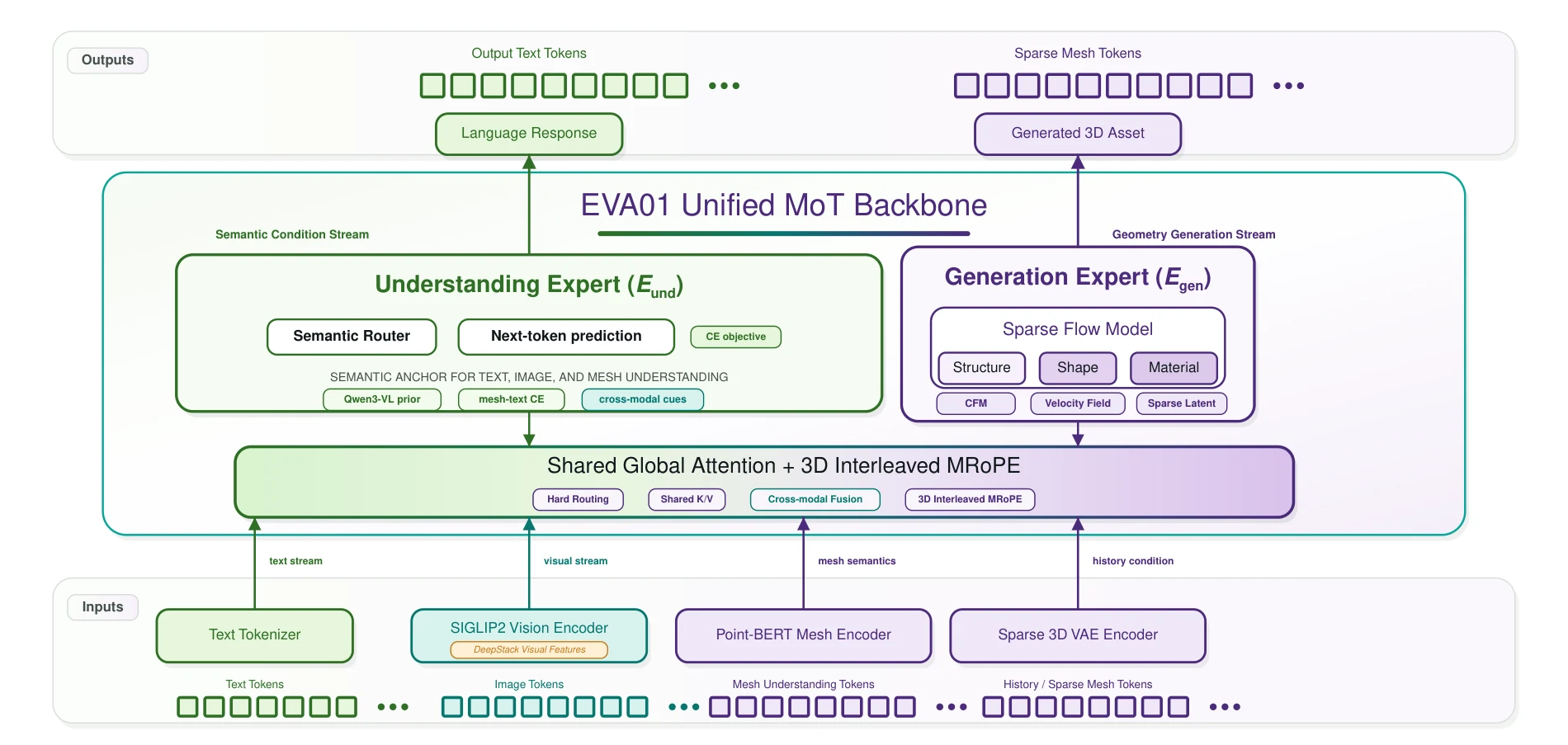
EVA01 splits the transformer into two structurally mirrored experts:
Understanding Expert ($E_{\text{und}}$) inherits pre-trained multimodal intelligence from Qwen3-VL. It processes text, images, and 3D point clouds through dedicated encoders — a standard text tokenizer, SigLIP2 for visual input, and Point-BERT for mesh geometry — all projected into a shared semantic space. This expert preserves the MLLM's language and visual priors.
Generation Expert ($E_{\text{gen}}$) mirrors $E_{\text{und}}$ structurally but is dedicated entirely to geometric synthesis. It generates 3D meshes through a three-stage flow matching pipeline: first predicting the sparse occupancy structure (which voxels are active), then synthesizing shape geometry within active voxels, and finally generating PBR material parameters — all within a continuous latent space rather than through discrete token prediction.
Attention
Routing is hard — determined strictly by modality. Text and image tokens go to $E_{\text{und}}$. Mesh tokens go to $E_{\text{gen}}$. No soft gating. No learned routing probabilities. The gradient paths are physically separated: $E_{\text{und}}$'s parameters never receive a gradient signal from the generation loss.
Attention is shared. Despite parameter isolation, both experts compute attention over the full sequence. $E_{\text{gen}}$'s queries attend to $E_{\text{und}}$'s keys and values while generating geometry. Semantic priors flow into geometric synthesis. The optimization landscapes remain independent.
$$Q_i = x_i W_Q^{(m_i)}, \quad K_i = x_i W_K^{(m_i)}, \quad V_i = x_i W_V^{(m_i)}$$
$$y_i = \operatorname{Attn}\bigl(Q_i, K, V; M\bigr) \, W_O^{(m_i)}$$
The key insight: parameter decoupling answers "where do gradients go," while shared attention answers "how does information flow." These are orthogonal concerns, and MoT addresses both without compromise.
Geometry Needs Coordinates
How to represent 3D geometry as a sequence of tokens is the most consequential decision in building a 3D-native MLLM. Get it wrong, and the model never converges.
EVA01 uses a sparse voxel grid representation at 512³ resolution. Each active voxel — those near the mesh surface — carries an explicit 3D coordinate $(x, y, z)$ alongside shape and material features. Inactive voxels in empty space do not exist in memory and consume no computation.
An alternative approach, VecSet, compresses geometry into a compact set of unordered latent vectors. It is popular for its efficiency. Our ablation experiments show that under unified sequence modeling, VecSet cannot produce usable geometry — the loss plateaus and the normalized score stays near zero.
The reason is fundamental. VecSet tokens carry no intrinsic spatial position. Flattened into an MLLM sequence, attention observes a weak global token identity but cannot distinguish where each token is located in 3D space. Without spatial anchors, the model must learn proximity implicitly from pure self-attention — and under the weak supervision of text-to-3D, this does not work.
Sparse voxel tokens bind each feature to an explicit coordinate. 3D Interleaved MRoPE repurposes Qwen3-VL's rotary position embeddings — originally designed for $(T, W, H)$ in 2D images — for $(x, y, z)$ grid coordinates. Rotary frequencies for each axis are interleaved across the feature vector, ensuring every dimension receives spatial signal from all three directions:
$$\operatorname{RoPE}(\mathbf{x}, \mathbf{p}) = \operatorname{Interleave}\bigl( \mathcal{R}_x(\mathbf{x}_{\mathcal{I}_x}), \mathcal{R}_y(\mathbf{x}_{\mathcal{I}_y}), \mathcal{R}_z(\mathbf{x}_{\mathcal{I}_z}) \bigr)$$
This injects a strong Euclidean inductive bias: tokens that are spatially adjacent receive correlated positional signals, enabling the attention mechanism to model local and global geometric relations directly. In long-context multi-turn editing, this is what prevents geometric drift across turns.
For generation, EVA01 uses conditional flow matching over continuous latents rather than autoregressive VQ token prediction. VQ tokenization projects continuous geometry onto a discrete codebook — an approximation that clips fine surface details and produces visible quantization artifacts. Flow matching regresses a velocity field directly in the continuous latent space, yielding smooth surfaces without discretization error.
Five Stages to a 3D-Native Model
Training a 3D-native MLLM is not a single-stage optimization. Capabilities that are not equally available at initialization must be introduced sequentially. EVA01 is trained through a five-stage curriculum — each stage enables what the next requires.
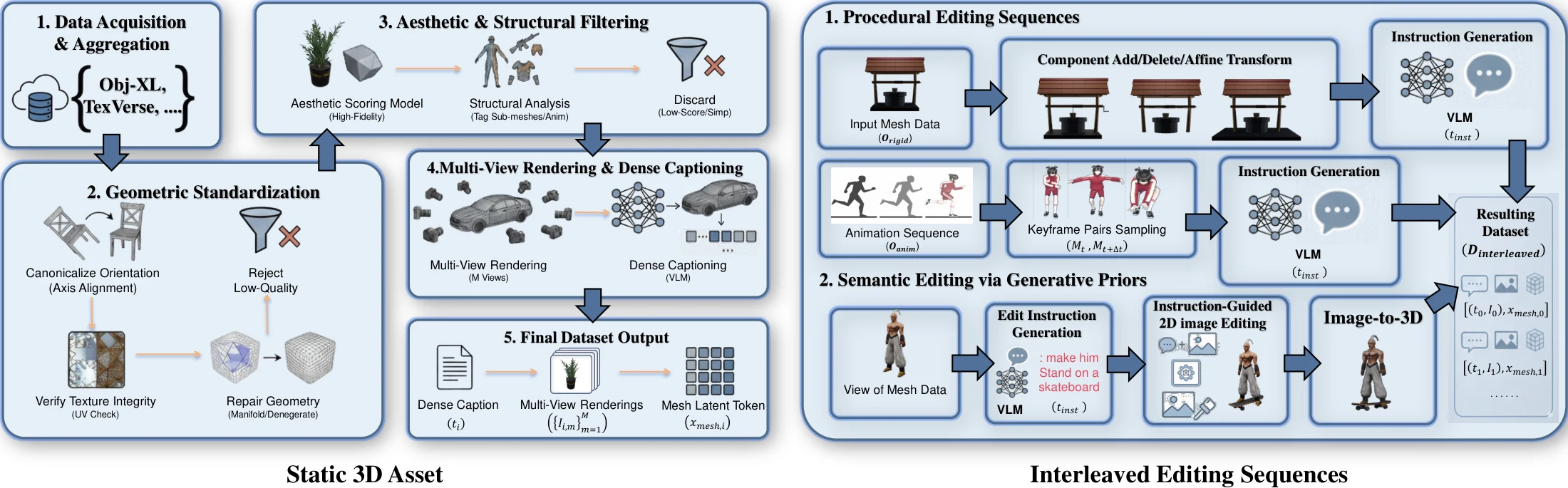
Stage 1 — Mesh Understanding Warm-up. Before the model can generate 3D, it must be able to read it. We train only a lightweight MLP projector that maps Point-BERT mesh features into Qwen3-VL's text embedding space. The entire backbone remains frozen. 20K steps.
Stage 2 — Visual-Geometric Initialization. The generation expert is trained with flow matching loss on image-conditioned samples, while the understanding expert is jointly trained on mesh-text captioning. This dual-objective setup creates synergy: captioning sharpens $E_{\text{und}}$'s geometric awareness, and through shared attention, these refined representations improve $E_{\text{gen}}$'s image-to-3D reconstruction. 150K steps.
Stage 3 — Semantic Modality Alignment. Triple-Batch Sampling constructs three independent training samples from each asset — conditioned on text, images, and mesh-text pairs. Dynamic image token dropout forces the network to reconstruct geometry from text alone when visual tokens are removed, implicitly transferring visual-geometric priors to the text pathway. 100K steps.
Stage 4 — Context-Aware Instruction Tuning. Using 3 million procedurally generated and 300,000 semantically synthesized editing trajectories, the model learns to predict the next geometric state conditioned on the full interaction history. A unified block attention mask allows current mesh tokens to attend to clean historical states while preventing future leakage. 80K steps.
Stage 5 — High-Quality Finetuning. Refines generation fidelity on a curated 400K high-quality asset subset at reduced learning rates. This sets the upper bound on geometric detail — surface curvature, fine structures, material definition. 30K steps.
Total: ~380K steps on 32 NVIDIA H20 GPUs with FSDP, bfloat16, and FlexAttention.
What the Model Can Do
Text-to-3D

EVA01 achieves a Fréchet Distance of 122.48 on Toys4K, compared to 238.45 for TRELLIS — a 49% reduction. Kernel Distance drops from 4.25 to 1.18. In user studies, EVA01 received 70.4% of all preferences, a nearly 5× margin over the next best method.
These gains are most visible on unusual compositions: "a pipe-organ levitation train," "a wingless supersonic vehicle," "a biomechanical clockwork heart." Prior methods satisfy fragments of such descriptions; EVA01 preserves the requested object identity and assembles semantically related parts into a coherent whole.
For image-to-3D, EVA01 achieves 87.28 CLIP and 61.74 FD, ranking second overall behind the specialist TRELLIS.2. EVA01 is the only unified model ranked in the top two for both modalities.
Multi-Turn Editing
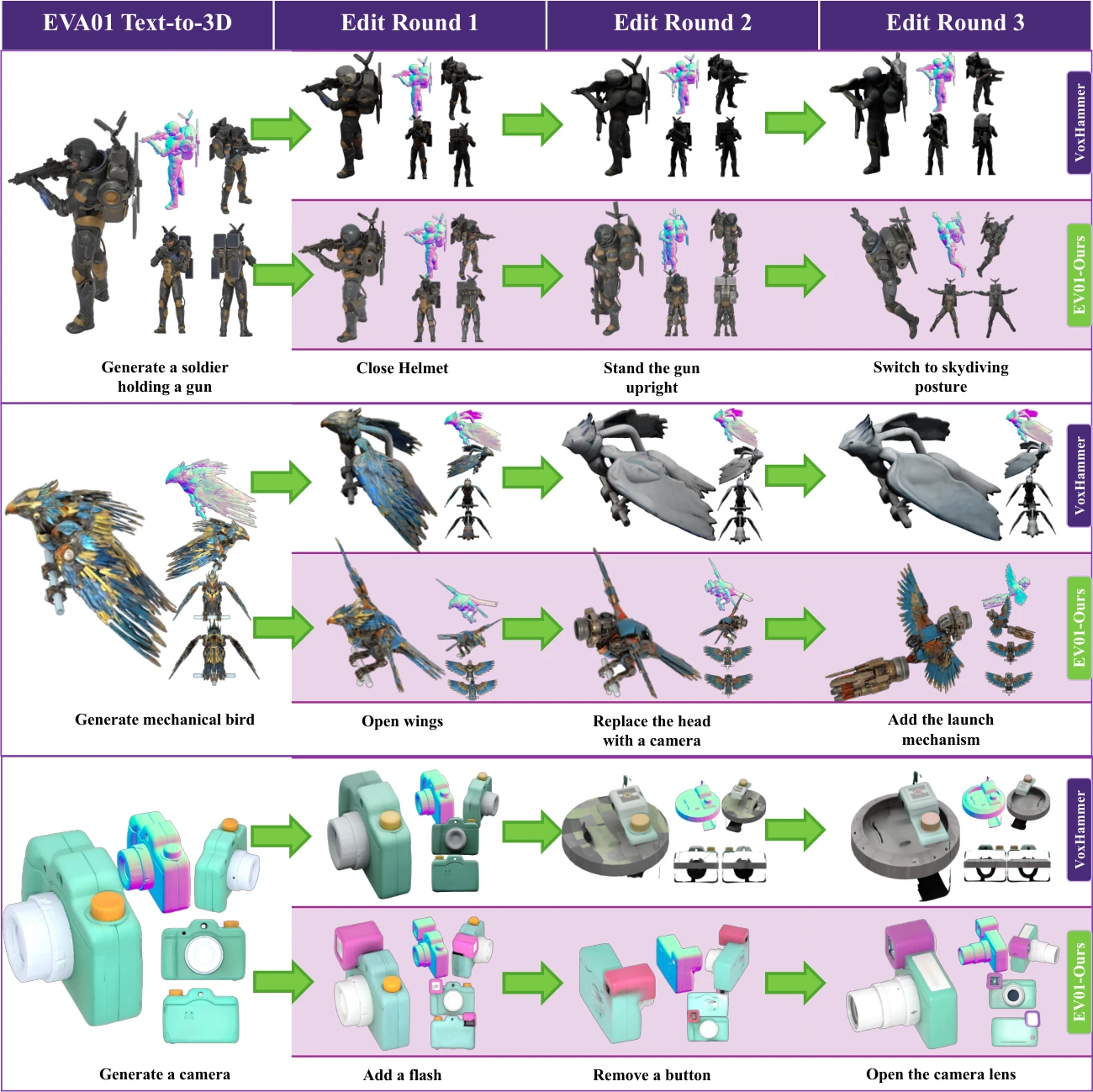
Multi-turn editing is EVA01's defining capability. Existing editing methods require explicit 3D masks to specify which regions to modify. EVA01 operates mask-free — it receives only the instruction and the accumulated history.
On our 400-sample editing benchmark, EVA01 achieves Fréchet Distance of 89.37 and 93.75% user preference, compared to 3.75% for the strongest mask-based baseline. Unedited-region consistency is preserved (Chamfer Distance 0.018 vs 0.015 for the mask-dependent best baseline), while instruction-following quality dominates (CLIP 70.18 vs 30.45).

The model handles diverse editing operations: adding and removing sub-meshes, replacing components, modifying materials, changing object state, and adjusting pose — all while preserving object identity across sequential turns.
Mesh Understanding
EVA01 reads 3D geometry as fluently as it reads text. On the PointLLM-200 captioning benchmark, EVA01-Final achieves a GPT-img score of 65.91 — a render-grounded metric where a judge compares the generated caption directly against multi-view renders. This exceeds the human-written reference captions' own GPT-img score of 56.05, reflecting the model's ability to produce detailed, visually grounded descriptions.
Three Design Principles for 3D-Native MLLMs
- Grid-based sparse latents are necessary for geometric validity. Unordered representations (VecSet) cannot converge under unified sequence modeling. Explicit spatial coordinates are a prerequisite, not an optimization.
- Modality dropout and multi-stage curriculum training are essential for bridging text and geometry. Text-conditioned 3D generation does not emerge from joint training alone. It must be explicitly distilled from visual-geometric priors through staged alignment.
- High-fidelity finetuning sets the final ceiling. After representation and alignment problems stabilize, a final stage on curated high-quality data determines the upper bound of geometric detail and surface quality.
Limitations and What Comes Next
EVA01 is a research milestone, not a finished product. Both experts operate at the 2B parameter scale with 512³ sparse-voxel resolution. The visual encoder — SigLIP2 with DeepStack — is a capable general-purpose vision model, but our representation analysis confirms it is a weaker dense geometric carrier than DINO-style self-supervised features. This limits image-to-3D fidelity relative to specialist reconstruction pipelines.
Scaling each expert toward 4B–8B, increasing resolution to 1024³, and upgrading the visual pathway to encoders that jointly preserve text alignment and dense patch structure are natural next steps. The understanding branch relies on point-cloud features while the generation branch operates on sparse-voxel latents — unifying these under a shared 3D latent substrate is a deeper architectural direction.
What EVA01 establishes is a template: semantic understanding and geometric generation decoupled in parameters, connected through shared attention, grounded in spatially structured representations, and trained through progressive curriculum learning. These principles scale independently of the specific scale at which they were demonstrated.
EVA01 research and model details: seeles.ai/research/pages/EVA01